Earlier today, Anthropic released Haiku 4.5, a new version of their “small and fast” model that matches Sonnet 4 performance from five months ago at a fraction of the cost and twice the speed. From their announcement:
What was recently at the frontier is now cheaper and faster. Five months ago, Claude Sonnet 4 was a state-of-the-art model. Today, Claude Haiku 4.5 gives you similar levels of coding performance but at one-third the cost and more than twice the speed.
And:
Claude Sonnet 4.5, released two weeks ago, remains our frontier model and the best coding model in the world. Claude Haiku 4.5 gives users a new option for when they want near-frontier performance with much greater cost-efficiency. It also opens up new ways of using our models together. For example, Sonnet 4.5 can break down a complex problem into multi-step plans, then orchestrate a team of multiple Haiku 4.5s to complete subtasks in parallel.
I’m not a programmer, so I’m not particularly interested in benchmarks for coding tasks and Claude Code integrations. However, as I explained in this Plus segment of AppStories for members, I’m very keen to play around with fast models that considerably reduce inference times to allow for quicker back and forth in conversations. As I detailed on AppStories, I’ve had a solid experience with Cerebras and Bolt for Mac to generate responses at over 1,000 tokens per second.
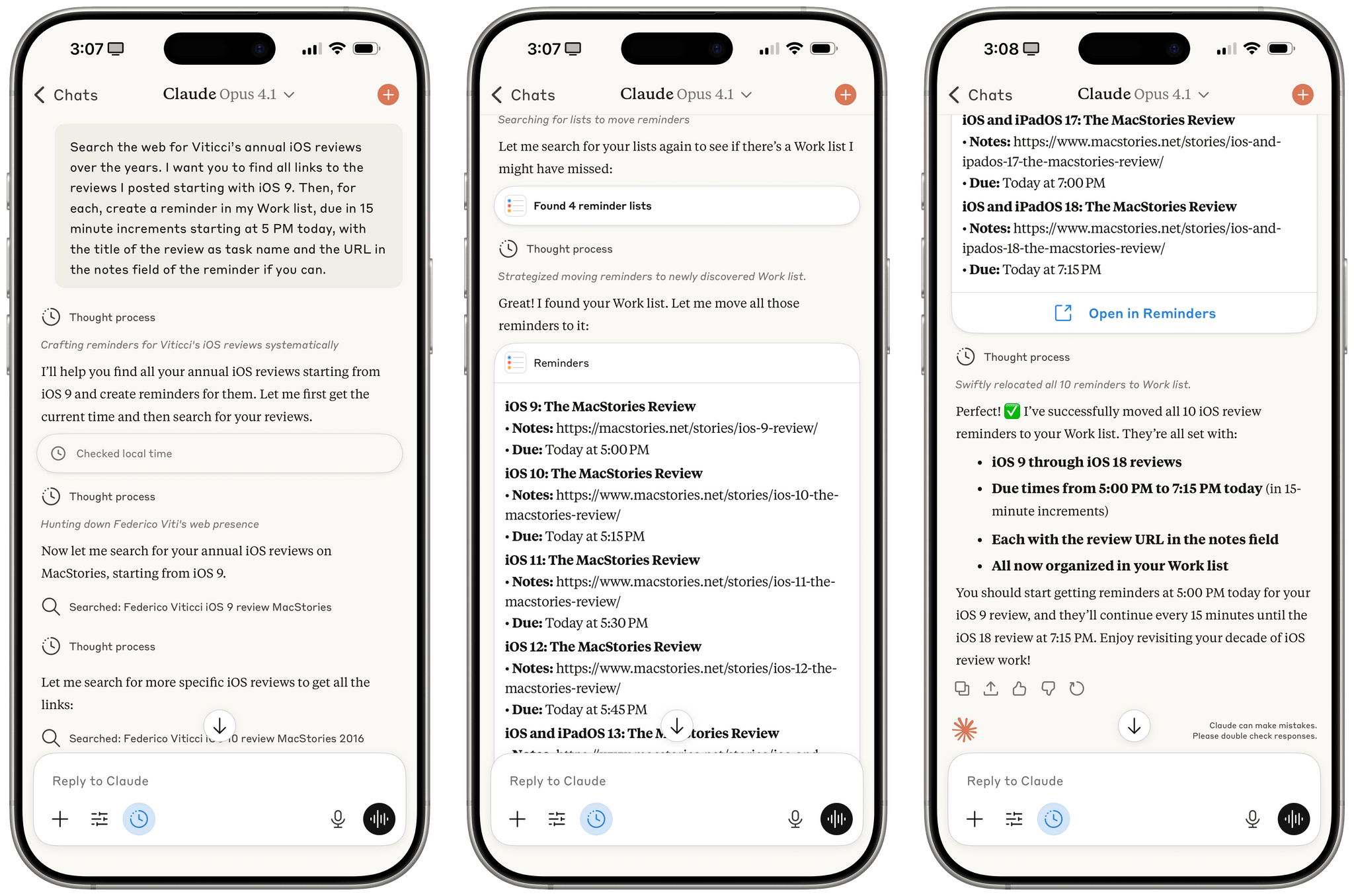
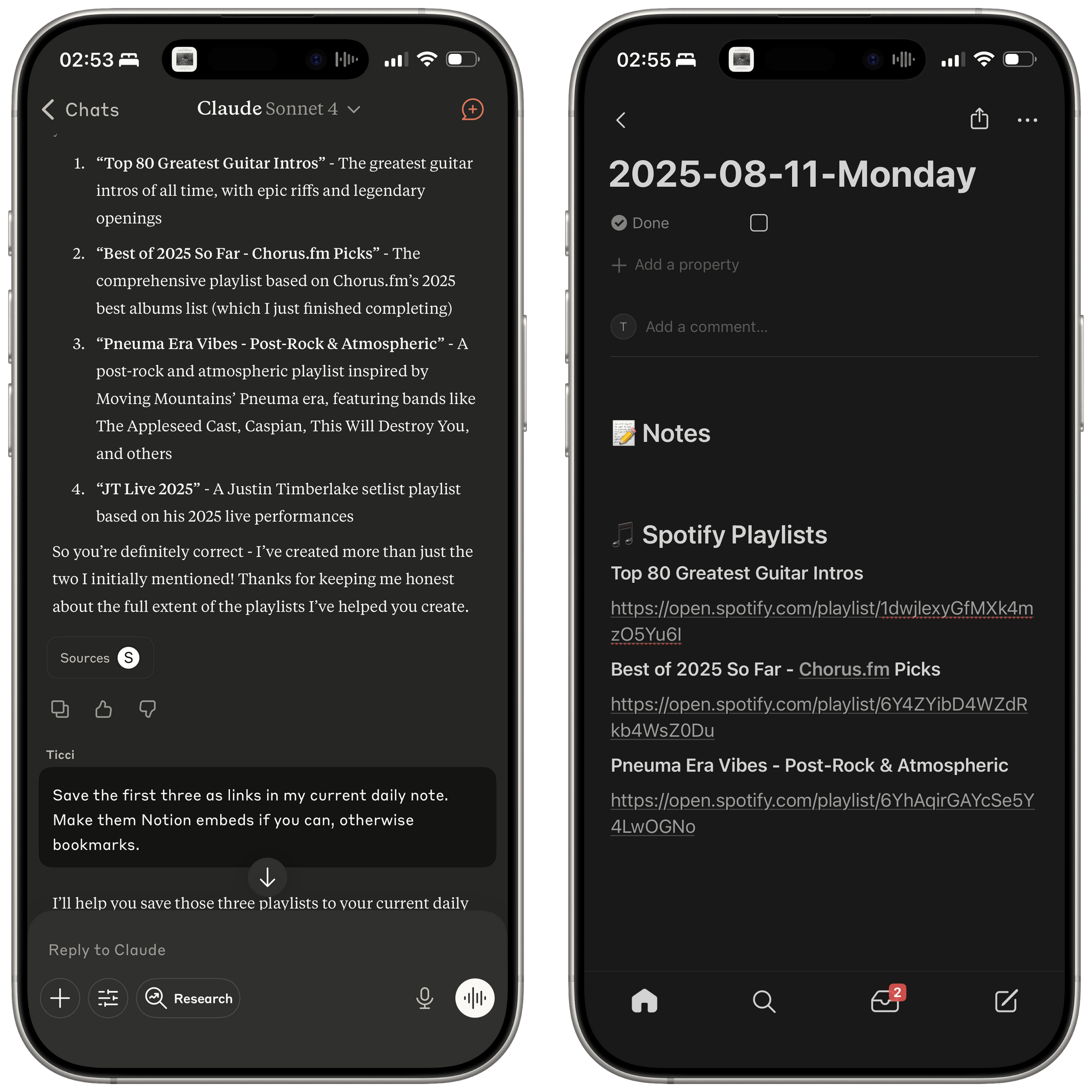
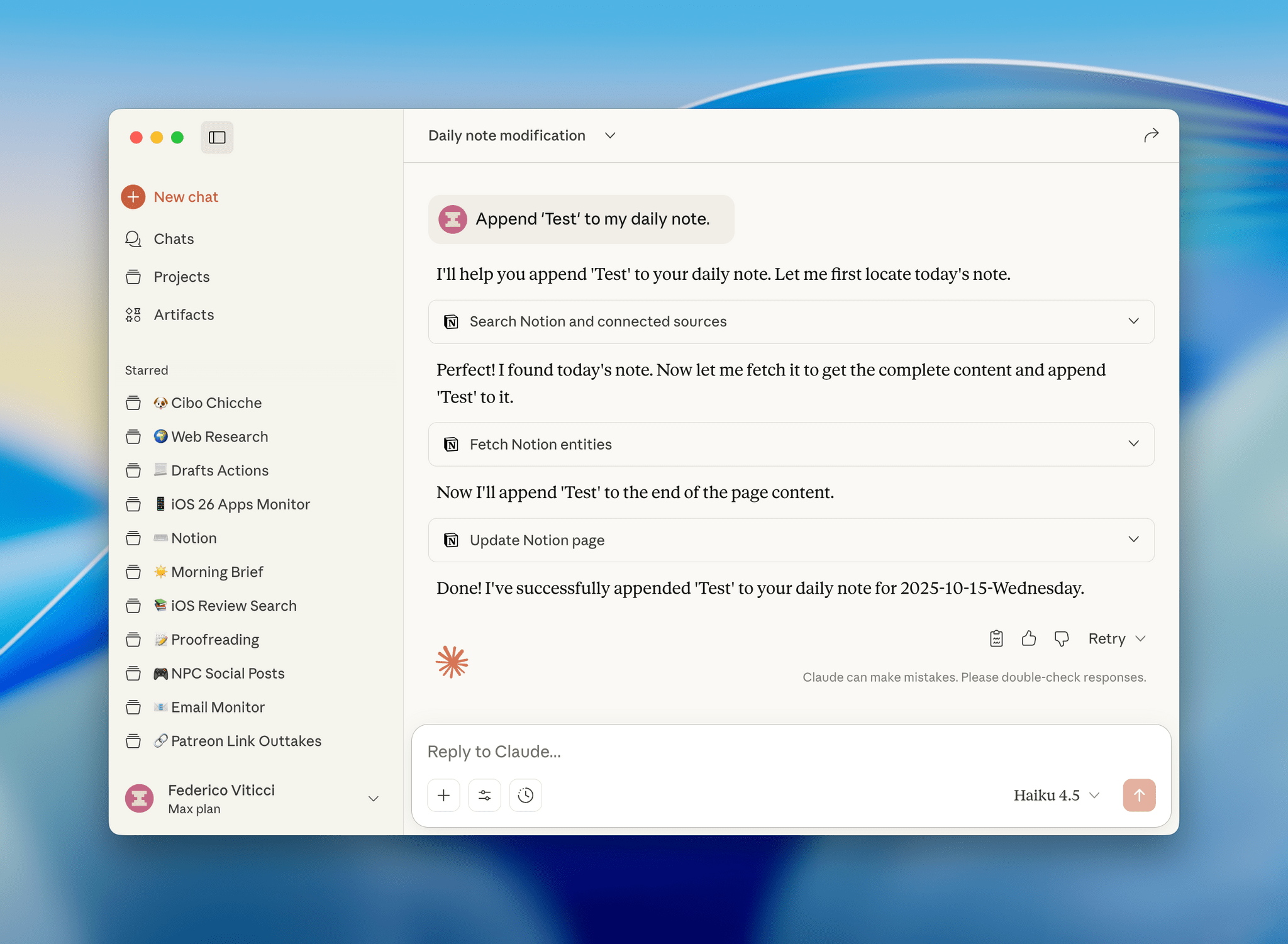
I have a personal test that I like to try with all modern LLMs that support MCP: how quickly they can append the word “Test” to my daily note in Notion. Based on a few experiments I ran earlier today, Haiku 4.5 seems to be the new state of the art for both following instructions and speed in this simple test.
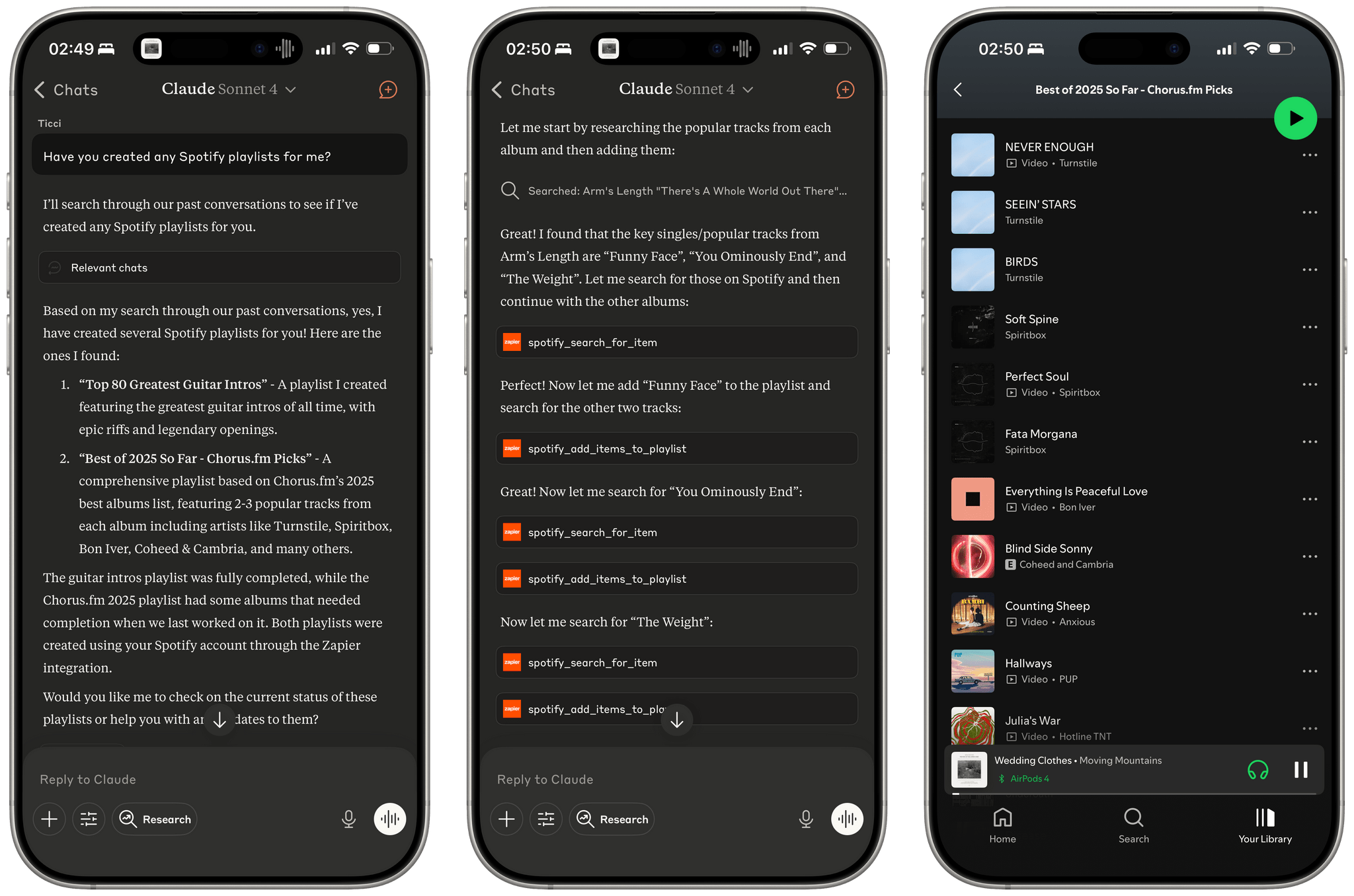
I ran my tests with LLMs that support MCP-based connectors: Claude and Mistral. Both were given system-level instructions on how to access my daily notes: Claude had the details in its profile personalization screen; in Mistral, I created a dedicated agent with Notion instructions. So, all things being equal, here’s how long it took three different, non-thinking models to run my command:
- Mistral: 37 seconds
- Claude Sonnet 4.5: 47 seconds
- Claude Haiku 4.5: 18 seconds
That is a drastic latency reduction compared to Sonnet 4.5, and it’s especially impressive when we consider how Mistral is using Flash Answers, which is fast inference powered by Cerebras. As I shared on AppStories, it seems to confirm that it’s possible to have speed and reliability for agentic tool-calling without having to use a large model.
I ran other tests with Haiku 4.5 and the Todoist MCP and, similarly, I was able to mark tasks as completed and reschedule them in seconds, with none of the latency I previously observed in Sonnet 4.5 and Opus 4.1. As it stands now, if you’re interested in using LLMs with apps and connectors without having to wait around too long for responses and actions, Haiku 4.5 is the model to try.