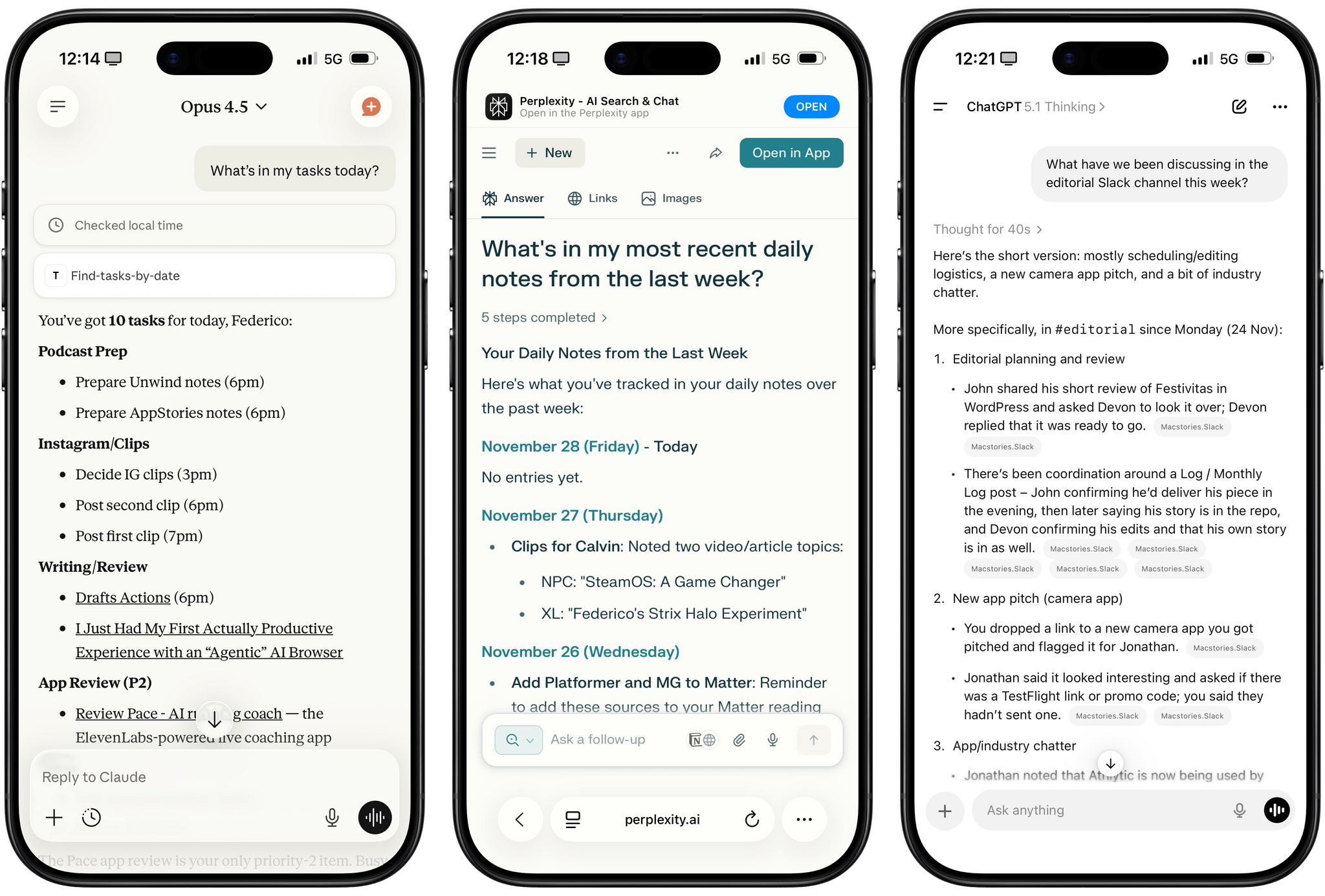
This week on AppStories, Federico and I talked about the personal productivity tools we’ve built for ourselves using Claude. They’re hyper-specific scripts and plugins that aren’t likely to be useful to anyone but us, which is fine because that’s all they’re intended to be.
Stu Maschwitz took a different approach. He’s had a complex shortcut called Drinking Buddy for years that tracks alcohol consumption and calculates your Blood Alcohol Level using an established formula. But because he was butting up against the limits of what Shortcuts can do, he vibe coded an iOS version of Drinking Buddy.
Two things struck me about Maschwitz’s experience. First, the app he used to create Drinking Buddy for iOS was Bitrig, which Federico and I mentioned briefly on AppStories. His experience struck a chord with me:
It’s a bit like building an app by talking to a polite and well-meaning tech support agent on the phone — only their computer is down and they can’t test the app themselves.
But power through it, and you have an app.
That’s exactly how scripting with Claude feels. It compliments you on how smart you are, gets you 90% of the way to the finish line quickly, and then tortures you with the last 10%. That, in a nutshell, is coding with AI, at least for anyone with limited development skills, like myself.
But the second and more interesting lesson from Maschwitz’s post is what it portends for apps in general. App Review rejected Drinking Buddy’s Blood Alcohol Level calculation on the basis of Section 1.4, the Physical Harm rule.
Maschwitz appealed and was rejected, even though other Blood Alcohol Level apps are available on the App Store. However, instead of pushing the rejection with App Review further, Maschwitz turned to Lovable, another AI app creation tool, which generates web apps. With screenshots from his rejected iOS app and a detailed spec in hand, Maschwitz turned Drinking Buddy into a progressive web app.
Maschwitz’s experience is a great example of what we covered on AppStories. App creation tools, whether they generate native apps or web apps, are evolving rapidly. And, while they can be frustrating to use at times, are limited in what they can produce, and don’t solve a myriad of problems like customer support that we detail on AppStories, they’re getting better at code quickly. Whether you’re building for yourself, like we are at MacStories, or to share your ideas with others, like Stu Maschwitz, change is coming to apps. Some AI-generated apps will be offered in galleries inside the tools that created them, others will be designed for the web to avoid App Review, and some will likely live as perpetual TestFlight betas or scripts sitting on just one person’s computer, but regardless of the medium, bringing your ideas to life with code has never been more possible.

{kind=link}