Earlier today, Anthropic announced that, similar to ChatGPT, Claude will be able to search and reference your previous chats with it. From their support document:
You can now prompt Claude to search through your previous conversations to find and reference relevant information in new chats. This feature helps you continue discussions seamlessly and retrieve context from past interactions without re-explaining everything.
If you’re wondering what Claude can actually search:
You can prompt Claude to search conversations within these boundaries:
- All chats outside of projects.
- Individual project conversations (searches are limited to within each specific project).
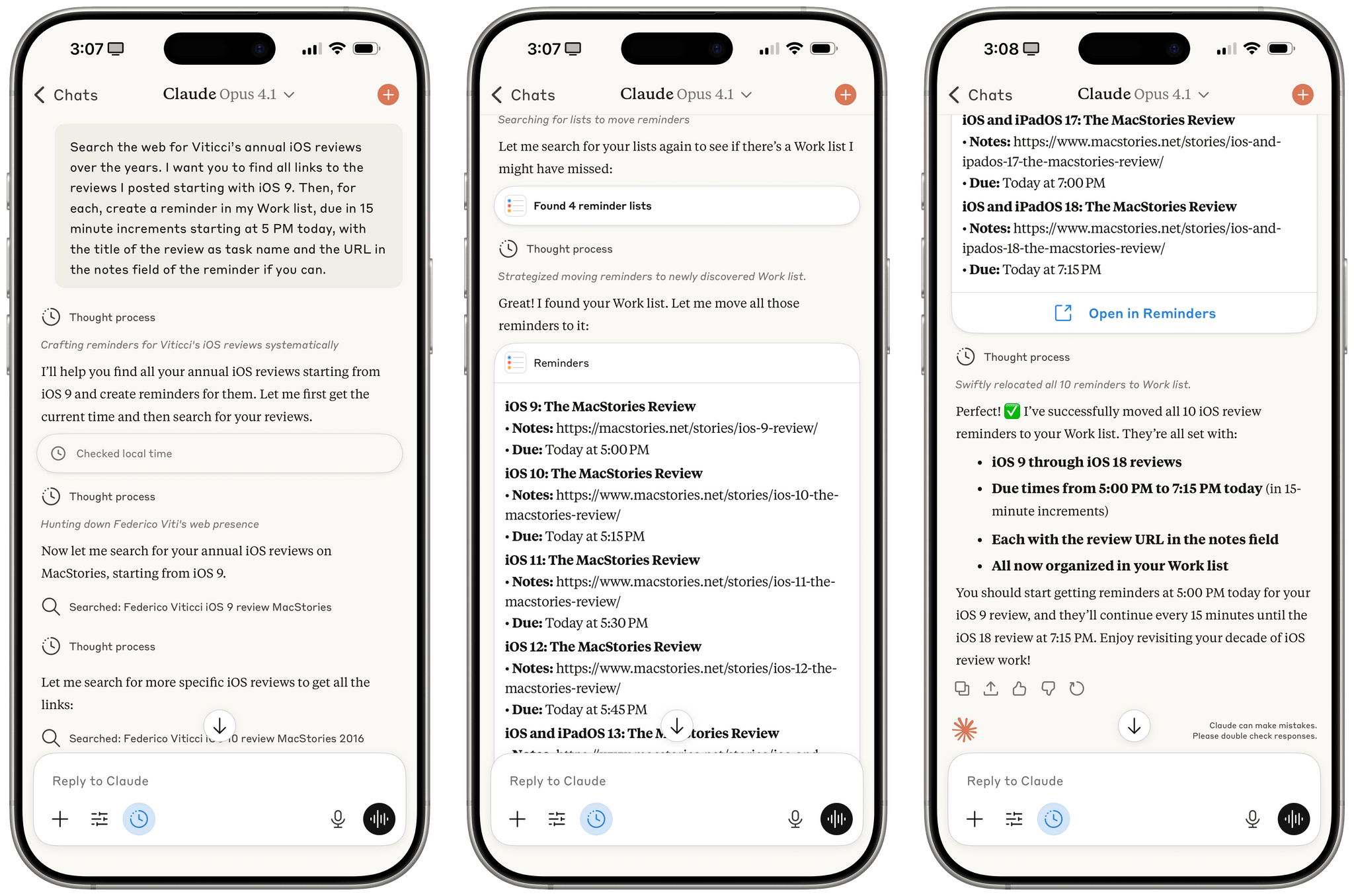
Conversation history is a powerful feature of modern LLMs, and although Anthropic hasn’t announced personalized context based on memory yet (a feature that not everybody likes), it seems like that’s the next shoe to drop. Chat search, memory with personalized context, larger context windows, and performance are the four key aspects I preferred in ChatGPT; Anthropic just addressed one of them, and a second may be launching soon.
As I’ve shared on Mastodon, despite the power and speed of GPT-5, I find myself gravitating more and more toward Claude (and specifically Opus 4.1) because of MCP and connectors. Claude works with the apps I already use and allows me to easily turn conversations into actions performed in Notion, Todoist, Spotify, or other apps that have an API that can talk to Claude. This is changing my workflow in two notable ways: I’m only using ChatGPT for “regular” web search queries (mostly via the Safari extension) and less for work because it doesn’t match Claude’s extensive MCP support with tools; and I’m prioritizing web apps that have well-supported web APIs that work with LLMs over local apps that don’t (Spotify vs. Apple Music, Todoist vs. Reminders, Notion vs. Notes, etc.). Chat search (and, again, I hope personalized context based on memory soon) further adds to this change in the apps I use.
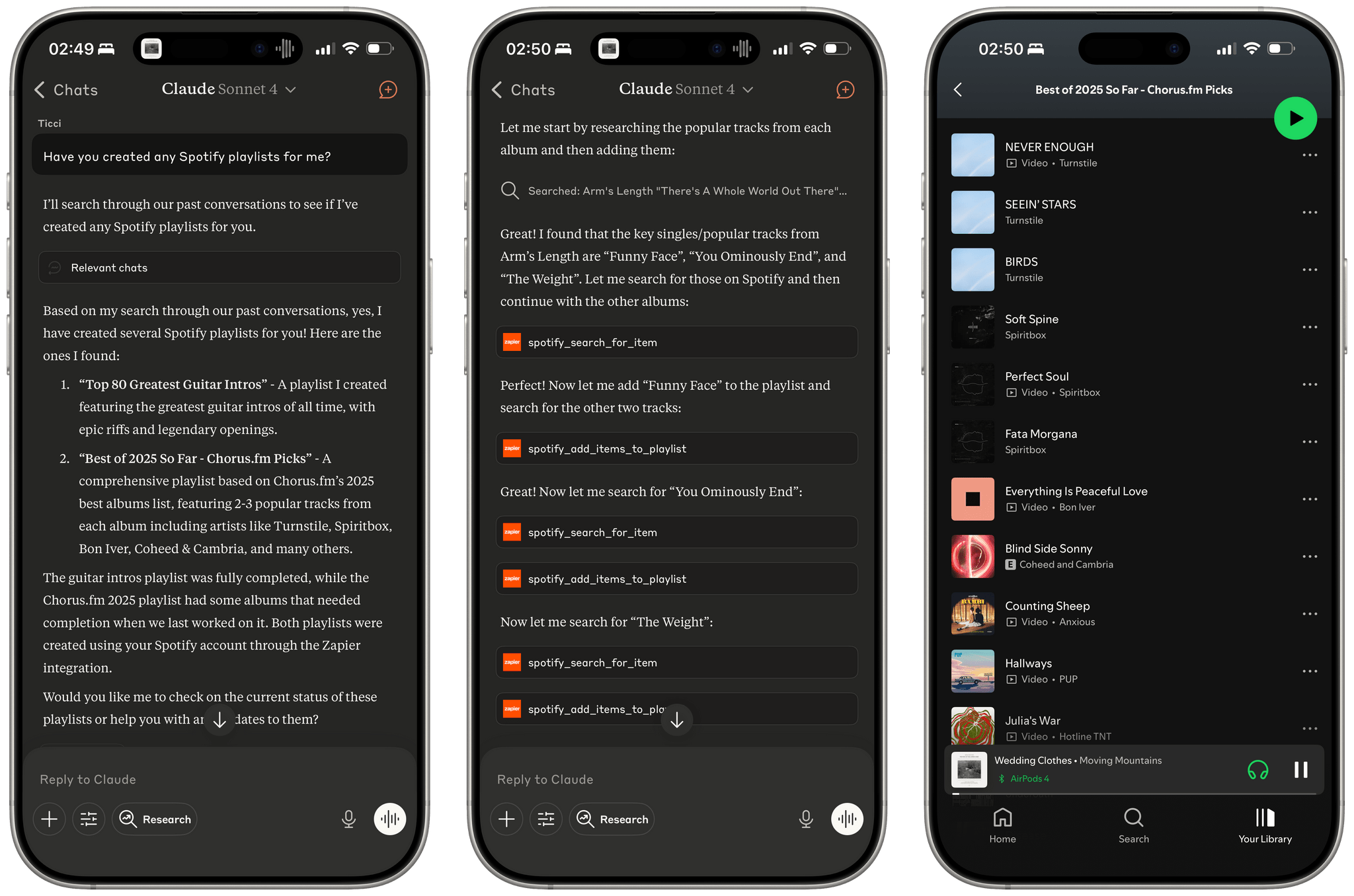
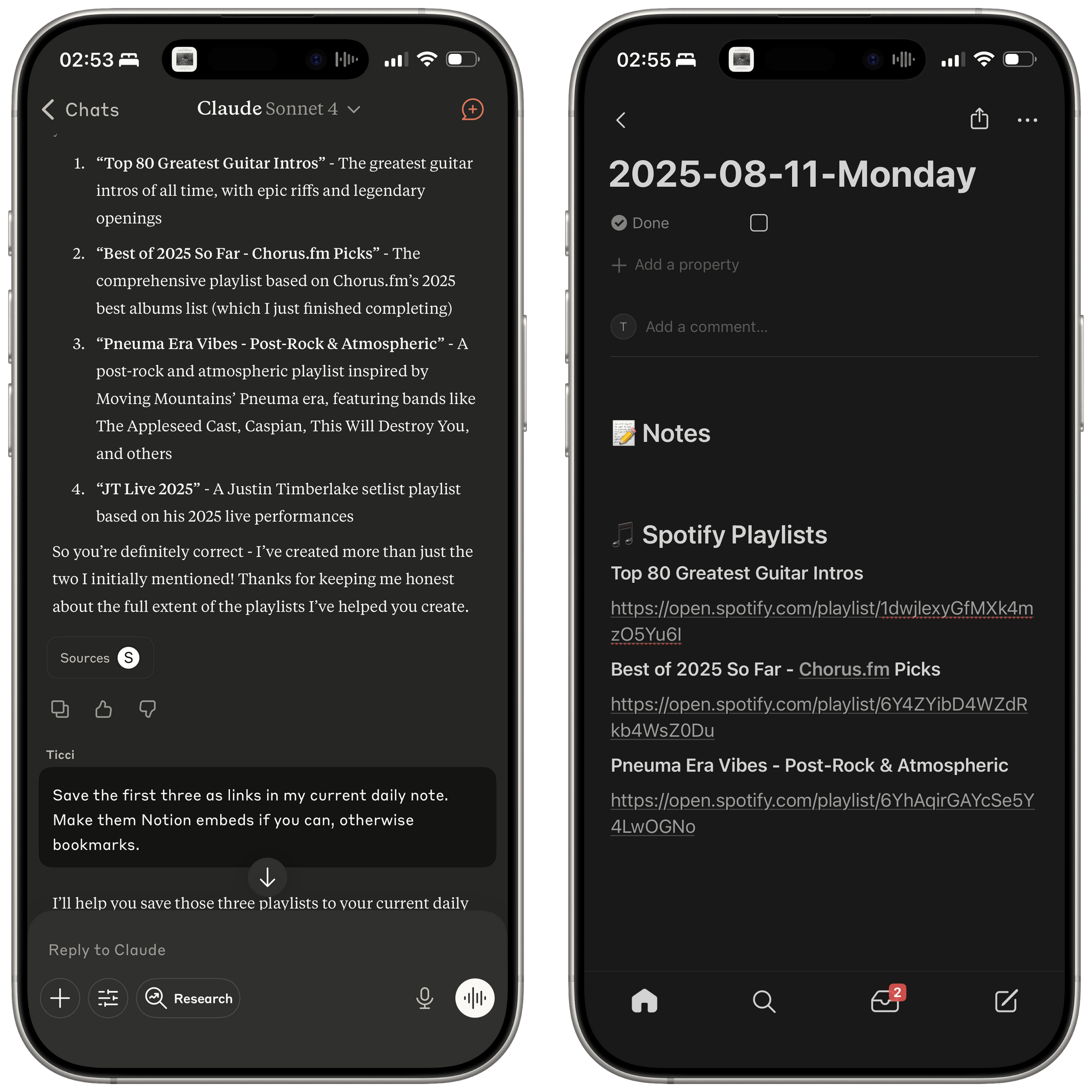
Let me offer an example. I like combining Claude’s web search abilities with Zapier tools that integrate with Spotify to make Claude create playlists for me based on album reviews or music roundups. A few weeks ago, I started the process of converting this Chorus article into a playlist, but I never finished the task since I was running into Zapier rate limits. This evening, I asked Claude if we ever worked on any playlists, it found the old chats and pointed out that one of them still needed to be completed. From there, it got to work again, picked up where it left off in Chorus’ article, and finished filling the playlist with the most popular songs that best represent the albums picked by Jason Tate and team. So not only could Claude find the chat, but it got back to work with tools based on the state of the old conversation.
Even more impressively, after Claude was done finishing the playlist from an old chat, I asked it to take all the playlists created so far and append their links to my daily note in Notion; that also worked. From my phone, in a conversation that started as a search test for old chats and later grew into an agentic workflow that called tools for web search, Spotify, and Notion.
I find these use cases very interesting, and they’re the reason I struggle to incorporate ChatGPT into my everyday workflow beyond web searches. They’re also why I hesitate to use Apple apps right now, and I’m not sure Liquid Glass will be enough to win me back over.